性能事件分析和通知
出现性能事件表示因集群组件争用而导致工作负载上出现 I/O 性能问题。Unified Manager 可对该事件进行分析,以识别所有涉及的工作负载和处于争用状态的组件,并确定该事件是否仍然为可能需要解决的问题。
Unified Manager 可监控集群上卷的 I/O 延迟(响应时间)和 IOPS(操作)。例如,当其他工作负载过度使用某个集群组件时,该组件将处于争用状态,且无法发挥出最佳性能水平来满足工作负载需求。使用同一组件的其他工作负载的性能也可能会受到影响,导致延迟增加。如果延迟超过动态性能阈值,Unified Manager 会触发性能事件以通知您。
事件分析
Unified Manager 使用过去 15 天的性能统计信息执行以下分析,以识别事件中涉及的受害者工作负载、抢夺者工作负载和集群组件:
- 识别延迟已超过动态性能阈值(即,延迟预测值的上限)的受害者工作负载:
- 对于硬盘或 Flash Pool(混合)聚合(本地层)上的卷,仅在延迟超过 5 毫秒(ms)且 IOPS 每秒操作数大于 10(ops/s)时触发事件。
- 对于全固态硬盘聚合或 FabricPool 聚合(云层)上的卷,仅在延迟超过 1 毫秒且 IOPS 大于 100 ops/s 时触发事件。
- 识别处于争用状态的集群组件。注集群互连时,如果受害者工作负载的延迟超过 1 毫秒,Unified Manager 会将其视为重要情况,并触发集群互连事件。
- 识别正在过度使用集群组件,并导致组件处于争用状态的抢夺者工作负载。
- 根据集群组件利用率或活动的偏差,对所涉及的工作负载进行排序,以确定对集群组件利用率改变最大的抢夺者工作负载以及受影响最大的受害者工作负载。
一些事件可能只会持续一小段时间,然后在其使用的组件不再处于争用状态后进行自我纠正。连续事件是指每隔五分钟就会在同一集群组件上重复发生并始终保持活动状态的事件。对于连续事件,Unified Manager 在连续两次的分析中均检测到相同事件后,就会触发警报。
事件状态
- 活动
- 指示性能事件当前处于活动状态(“新”或“已确认”)。导致该事件的问题尚未自我纠正或未得到解决。存储对象的性能计数器仍高于性能阈值。
- Obsolete(废弃)
- 指示事件不再处于活动状态。导致该事件的问题已自我纠正或已得到解决。存储对象的性能计数器不再高于性能阈值。
事件通知
“Dashboard(仪表板)”页面和用户界面的许多其他页面都会显示事件,这些事件的警报将被发送到指定的电子邮件地址。可在“Event details(事件详细信息)”页面和“Workload Analysis(工作负载分析)”页面查看事件的详细分析信息,并获取相关解决建议。
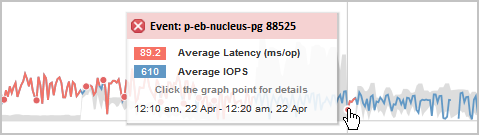
在此示例中,“Latency(延迟)”图上的红点( )表示事件。将鼠标光标悬停在红点上方,会出现一个弹出窗口,其中包含有关事件的更多详细信息以及分析选项。
)表示事件。将鼠标光标悬停在红点上方,会出现一个弹出窗口,其中包含有关事件的更多详细信息以及分析选项。
事件交互
在“Event details(事件详细信息)”页面和“Workload Analysis(工作负载分析)”页面,可通过以下方式与事件交互:
- 将鼠标移动到某个事件上,会出现一条消息,其中显示了事件 ID 以及检测到该事件的日期和时间。
如果在同一时间段内有多个事件,该消息将显示事件数量。
- 单击某个事件会出现一个对话框,其中显示了有关该事件的更多详细信息,包括涉及的集群组件。
处于争用状态的组件会被圈出并以红色突出显示。可单击事件 ID 或 View full analysis(查看完整分析),在“Event details(事件详细信息)”页面查看完整分析结果。如果在同一时间段内有多个事件,该对话框将显示最近三个事件的详细信息。可单击事件 ID,在“Event details(事件详细信息)”页面查看事件分析结果。