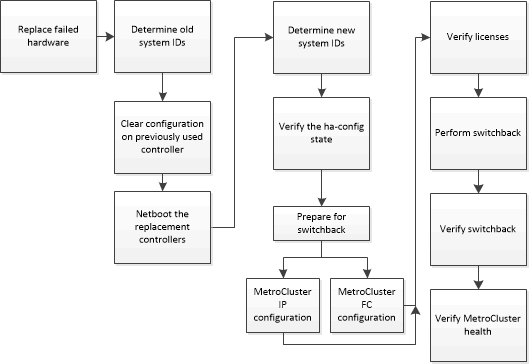
从多控制器或存储故障中恢复从多控制器或存储故障中恢复如果控制器故障在四节点或八节点 MetroCluster 配置中扩展到 DR 组一侧的所有控制器模块,或者已更换存储,则必须更换设备并重新分配驱动器的所有权才能从灾难中恢复。开始之前在决定使用此过程之前,应查看可用的恢复过程。选择正确的恢复过程必须隔离灾难站点。隔离灾难站点。必须已执行切换。执行强制切换替换驱动器和控制器模块必须是从未分配过所有权的新模块。关于本任务此过程中的示例显示了四节点配置。如果是八节点配置(两个 DR 组),则必须考虑其他控制器模块上的任何故障并对其执行所需的恢复任务。此过程使用以下工作流程:更换灾难站点的硬件如果需要更换硬件组件,则必须参考各自的硬件更换和安装指南进行更换。确定旧控制器模块的系统标识更换灾难站点的所有硬件后,必须确定替换控制器模块的系统标识。将磁盘重新分配给新控制器模块时,需要旧的系统标识。将替换驱动器与幸存站点隔离(MetroCluster IP 配置)必须通过从幸存节点断开 MetroCluster iSCSI 发起方连接来隔离所有替换驱动器。清除以前使用的控制器模块上的配置如果控制器模块先前已使用过但不是直接从 Lenovo 接收的,则在 MetroCluster 配置中使用该控制器模块作为替换控制器模块之前,必须清除先前存在的配置。对新控制器模块进行网络引导如果新控制器模块的 ONTAP 版本与幸存控制器模块上的版本不同,则必须对新控制器模块进行网络引导。确定替换控制器模块的系统标识更换灾难站点的所有硬件后,必须确定新安装的一个或多个存储控制器模块的系统标识。验证组件的 ha-config 状态在 MetroCluster 配置中,控制器模块和机箱组件的 ha-config 状态必须设置为 mcc,确保它们可以正常引导。准备灾难站点以进行切回必须执行相应步骤来准备切回操作。需要执行的步骤取决于您的配置。为 FabricPool 配置(MetroCluster IP 配置)重新建立对象存储如果 FabricPool 镜像中的对象存储之一与 MetroCluster 灾难站点位于同一位置并被销毁,则必须重新建立对象存储和 FabricPool 镜像。验证替换节点上的许可证如果受损节点使用了需要标准(节点锁定的)许可证的 ONTAP 功能,则必须为替换节点安装新的许可证。对于采用标准许可证的功能,集群中的每个节点都应有自己的功能密钥。执行切回修复 MetroCluster 配置后,可以执行 MetroCluster 切回操作。MetroCluster 切回操作可将配置恢复到其正常运行状态,使灾难站点上的同步源存储虚拟机(SVM)处于活动状态并开始从本地磁盘池提供数据。验证切回是否成功执行切回后,需要确认所有聚合和存储虚拟机(SVM)均已切回并联机。镜像替换节点的根聚合(MetroCluster IP 配置)如果更换了磁盘,必须镜像灾难站点上新节点的根聚合。重新配置 ONTAP Mediator 服务(MetroCluster IP 配置)如果具有配置了 ONTAP Mediator 服务的 MetroCluster IP 配置,则必须删除并重新配置与 Mediator 的关联。验证 MetroCluster 配置是否正常应检查 MetroCluster 配置的运行状况以验证是否正常运行。提供反馈