Storage high availability
The two storage controllers in a storage block operate in active-passive mode, with automatic failover when the failure of a storage controller is detected.
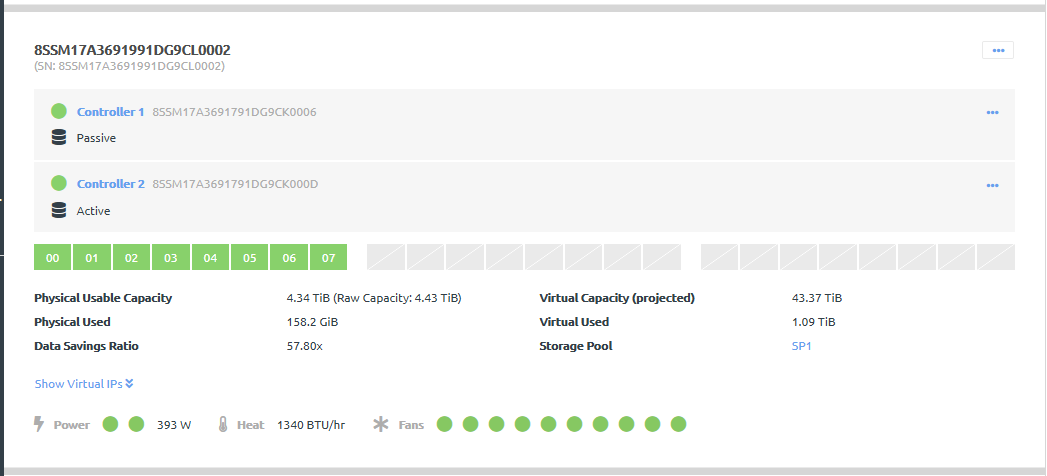
The storage controllers send heartbeats every four seconds to the internal interconnect, which acts as the quorum node. If the internal interconnect does not receive a heartbeat for 32 seconds from the active storage controller, it triggers a storage controller failover. The secondary controller takes over in 60-90 seconds, with no data loss, and no rebuilds needed. Any new or in-flight I/O operations will hang until the failover completes because the iSCSI timeouts are set to be greater than the failover time.1
RAID 50 and hot-sparing are used for storage redundancy of the Flash SSDs. Each group of eight SSDs is organized as a 6+P+S RAID-5 array, and data is striped across the multiple2 RAID-5 arrays in a storage block to make it a RAID-50 array. This protects against the failure of flash drives. When a drive fails, the data from that failed drive is automatically rebuilt and written to the spare drive. The rebuild operation will impose some small background load on that group of eight drives, but user reads and writes are always prioritized higher than the background rebuild operations.
It is important to replace the failed drive as soon as possible.3 The replaced drive will then become the new hot spare drive for the RAID group. If the failed drive is not replaced, the array is operating without a hot spare - this is not recommended as there will be nowhere to rebuild data to if a second drive fails in this group of drives. If a second drive fails during the multi-hour rebuild process, or if a drive sector is unreadable during the rebuild process, which is a double failure, there will be a data loss. In this case, to recover the lost data, the customer will need to go back to a prior quick DR backup on a different storage pool.
In addition to ECC, each Flash drive further uses erasure coding to handle uncorrectable errors within the drive. If an error is not correctable by either the ECC or the erasure coding on the drive, we will use the RAID to recover that data.
The platform supports application-consistent backups4 and clones. Both scheduled backups and user-generated backups are supported on the platform. If a VM gets damaged or corrupted due to any reason, such as a software crash or bug or a virus or other form of security attack, it is possible to simply revert back to a previous backup; or, you can start a new VM against a backup. Of course, any updates since the most recent backup will be lost.
If an operator error causes a single file to be mistakenly deleted, we allow a single file to be restored from a backup.5
The ThinkAgile CP platform supports disaster recovery (DR). VMs provisioned in virtual datacenters with access to more than one storage pool can turn on disaster recovery. This will allow the VM backups to be sent to a storage pool (possibly at a remote physical site) different than the one that holds the VM vDisks.
If the DR storage pool is at the same site, it can be used to recover from the double failures described previously. If the DR storage pool is at a secondary site, then it can be used to recover from disasters such as earthquakes, hurricanes, floods, and so on, which affect everything at a primary site. In this case, the backups at the secondary site can be used to recover and continue the IT operations. The time to recover at the secondary site, called the Recovery Time Objective (RTO) can be small; the amount of data lost when disaster strikes, called the Recovery Point Objective (RPO), can be as small as the last minute's worth of data updates.
For more information about setting up quick DR backups, see the following topic: