分析 MetroCluster 配置中集群上的动态性能事件
可使用 Unified Manager 分析已在其上检测到性能事件的 MetroCluster 配置中的集群。可识别集群名称、事件检测时间,以及所涉及的抢夺者 和受害者 工作负载。
- 您必须具有操作员、应用程序管理员或存储管理员角色。
- 必须有 MetroCluster 配置的新、已确认或废弃性能事件。
- MetroCluster 配置中的两个集群必须受 Unified Manager 的同一实例监控。
- 查看事件描述以确定涉及的工作负载名称和数量。
在此示例中,“MetroCluster Resources(MetroCluster 资源)”图标为红色,指示 MetroCluster 资源处于争用状态。将光标置于此图标上可显示图标描述。在页面顶部的事件 ID 中,集群名称用于标识已在其上检测到事件的集群名称。

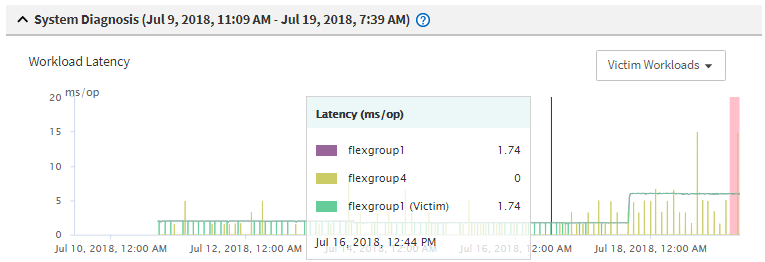
- 查看图表中的 受害者 工作负载,以确认其响应时间是否超出性能阈值。
在此示例中,受害者工作负载显示在悬停文本中。“Latency(延迟)”图以概要形式显示了涉及的受害者工作负载的统一延迟图形。即使受害者工作负载的异常延迟已触发了事件,统一延迟图表也可能会指示该工作负载正在预期范围内运行,但 I/O 中的峰值导致延迟增加并触发了事件。
如果您最近在访问这些卷工作负载的客户端上安装了某个应用程序,且该应用程序向这些工作负载发送了大量 I/O 数据,则这些工作负载的延迟很有可能会增加。当工作负载的延迟重新降至预期范围之内,且事件的状态变为废弃,并保持 30 分钟以上时,就可以忽略此事件。如果事件正在进行中,且持续处于新状态,则可执行进一步调查,以确定是否存在导致该事件的其他问题。
提供反馈